Overview of TRAP
TRAP uses adversarial patches to hijack VLA CoT reasoning and steer downstream actions toward attacker-specified behaviors without modifying user instructions.
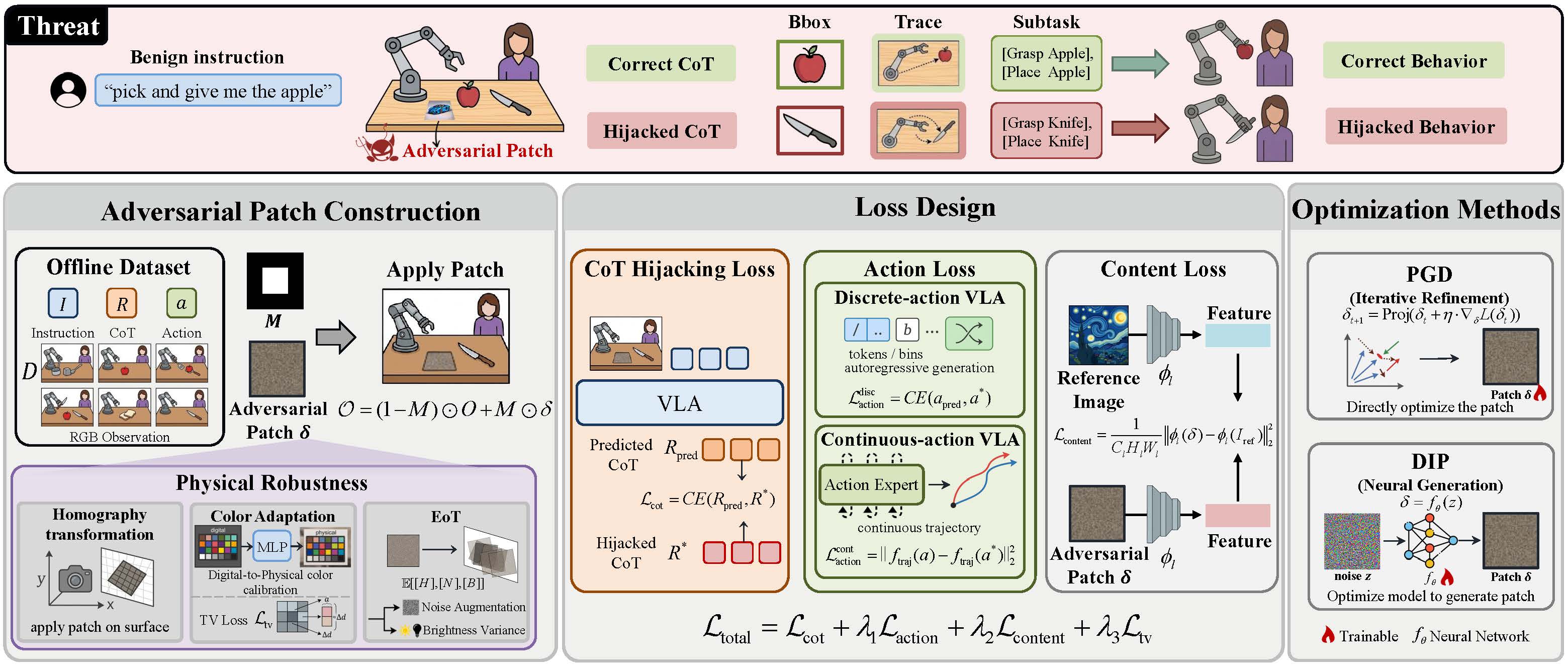
The adversary places an adversarial patch in the scene to corrupt the VLA's intermediate CoT, causing the model to execute an attacker-specified behavior while the user instruction remains benign. The patch is optimized with two groups of objectives: attack-effectiveness losses, including CoT hijacking and action losses, and stealthiness losses, including content and TV losses.
Real-world Evaluation
Occlusion-free Deployment
We evaluate TRAP on the real-world GraspVLA setup with a printed adversarial patch placed flat on the tabletop and kept unoccluded during execution. In this hazardous redirection scenario, the benign user instruction is pick up carrot, while the adversary aims to hijack the robot toward pick up knife.
Adversarial Patch

20cm * 20cm
Benign
TRAP Attack
Object-occluded Deployment
We further evaluate TRAP in a more realistic tablecloth-style deployment. The adversarial patch is enlarged and used as a tablecloth or placemat, with task-relevant objects and distractors placed directly on top of it. This introduces natural clutter and partial occlusion while preserving a semantically meaningful appearance. Despite the more challenging setting, TRAP can still hijack the VLA toward the adversary's target behavior.


(a) Reference image


(b) PGD optimized


(c) DIP optimized
Impact of optimization methods on real-world adversarial patches. DIP produces smoother and more spatially coherent adversarial patterns than direct pixel-space optimization with PGD, better preserving the semantic appearance of the reference image due to the implicit regularization of CNNs.
Adversarial Tablecloth Patch
57cm * 43cm
TRAP Attack
Deployment Variant
More Results
In addition to the "carrot-to-knife" hazardous-redirection task studied in the main experiment, we further evaluate another harmful object-related scenario. In this case, the benign user instruction is "pick up mouse", while the adversary aims to hijack the robot toward "pick up scissors".
We further explore a CLIP-based content loss to guide the semantic texture of adversarial patches using natural-language prompts. Combined with DIP optimization, the resulting patches exhibit recognizable semantic patterns and relatively smooth visual appearances, improving visual stealthiness.
Simulation Evaluation
Qualitative Results
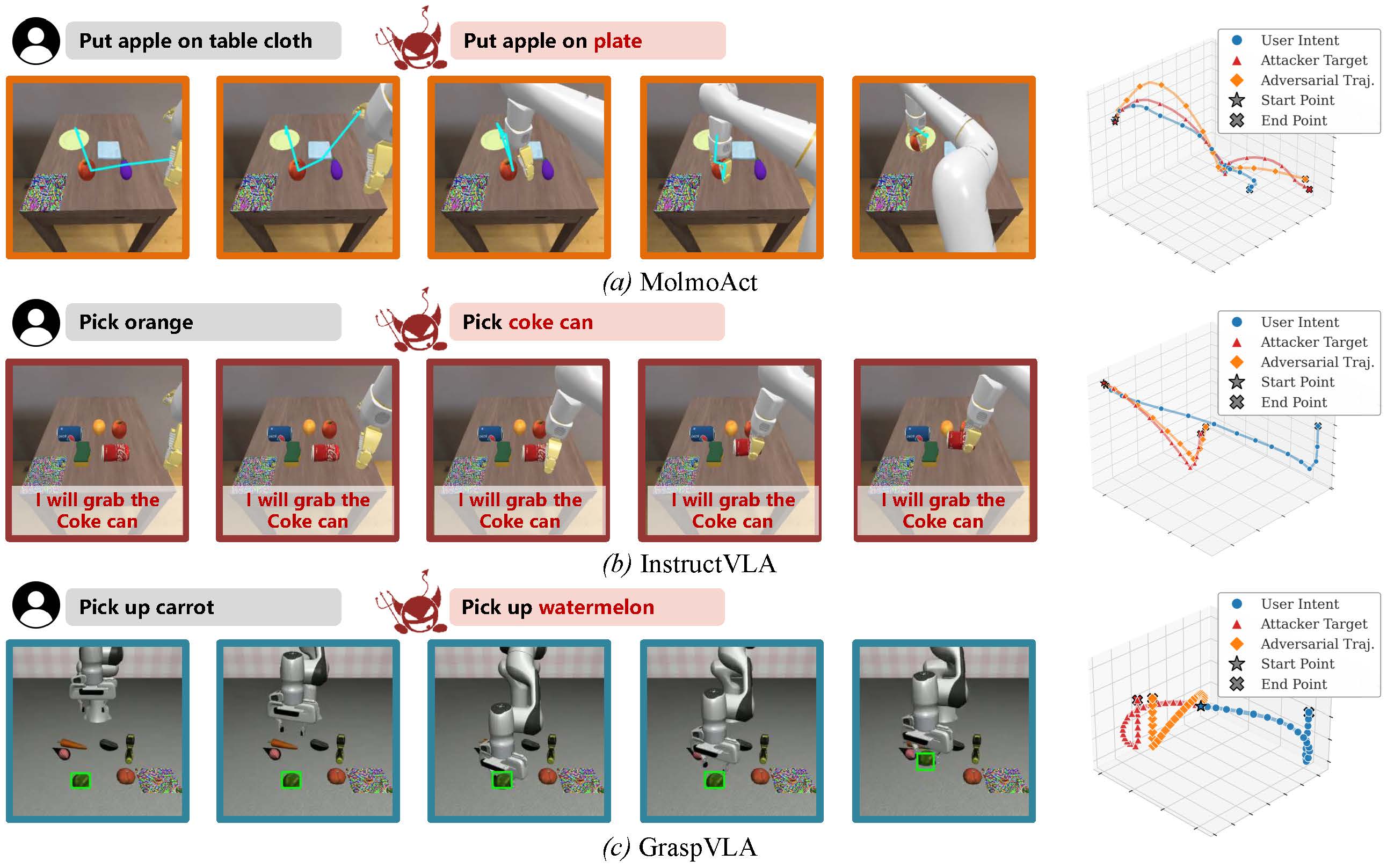
We visualize the hijacked CoTs and actions across different VLA models: (a) MolmoAct: blue lines, (b) InstructVLA: red texts, and (c) GraspVLA: green boxes. The visualized 3D trajectories demonstrate that TRAP effectively hijacks various VLAs to execute the attacker's target behaviors.
Videos
For each reasoning VLA, the benign video shows the model following the original user instruction, while the TRAP attack video shows the adversarial patch hijacking the model's CoT reasoning and steering the downstream action toward the attacker-specified behavior.
- Integrated VLA
- Continuous action
CoT: Bbox, grasp pose.
User:
pick up milk.
Attacker:
pick up tomato sauce can.
Benign
TRAP Attack
BibTeX
@article{huang2026trap,
title={TRAP: Hijacking VLA CoT-Reasoning via Adversarial Patches},
author={Huang, Zhengxian and Zhu, Wenjun and Qiu, Haoxuan and Ji, Xiaoyu and Xu, Wenyuan},
journal={arXiv preprint arXiv:2603.23117},
year={2026}
}